

Short answer. Your agent guesses confidently instead of saying "I don't know" because the way models are scored rewards a lucky guess over an honest abstention. In a chatbot that is a wrong answer; in an agent it is a wrong action taken. Reward honest uncertainty in your own evaluation, calibrate the agent's confidence into a usable signal, and route low-confidence or high-stakes moments to a human, and the agent becomes safe to give real autonomy.

At the edge of what it knows, the agent strides confidently into the fog rather than stopping to ask. Hero image.
Key facts.
- The incentive is the root cause: OpenAI's 2025 analysis argues models hallucinate because accuracy-only evaluations reward a confident guess over an honest "I don't know", so models are effectively trained to bluff (Kalai et al., Why Language Models Hallucinate, arXiv:2509.04664, 2025).
- Errors should cost more than abstentions, but most scoreboards score them the same, so a guessing model outranks an abstaining one even when it is confidently wrong far more often (OpenAI, 2025).
- It is not inevitable: the same work shows models can abstain when uncertain, so hallucination stems from misaligned evaluation, not an unfixable property of the model (OpenAI, 2025; Nature, 2026).
- Being calibrated is cheap: the paper notes that being calibrated, having confidence match accuracy, takes far less computation than being accurate, so honest uncertainty is within reach (OpenAI, 2025).
Why does a confident wrong answer beat an honest "I don't know"?
Because of how we grade. Almost every benchmark and leaderboard scores a model on accuracy, counting right answers, and treats a wrong answer and an abstention the same, as simply not-right. Under that rule, a model that always guesses will outscore a model that sometimes says "I don't know", because guessing occasionally lands a point while abstaining never does. OpenAI's 2025 analysis makes this the central claim: hallucinations persist because the scoreboard rewards confident guessing over honest uncertainty, so models are optimized to bluff. The behavior is not a mysterious flaw. It is the rational response to the test. An agent built on a model trained that way will, by default, produce a fluent confident answer rather than admit it does not know, which is exactly the behavior you do not want when the answer feeds a real action.
What is calibration, and why do agents lack it?
Calibration means the model's stated confidence matches how often it is actually right: when it says it is 90% sure, it should be correct about 90% of the time. A well-calibrated agent can be trusted to know when it does not know. Most deployed agents are poorly calibrated, reporting high confidence on answers that are wrong, because the training objective rewarded sounding sure. The OpenAI work adds a useful point here: being calibrated takes far less computation than being accurate. The agent does not have to know everything. It has to know the boundary of what it knows. That boundary is what lets it abstain or escalate instead of guessing, and it is the part standard training neglects.
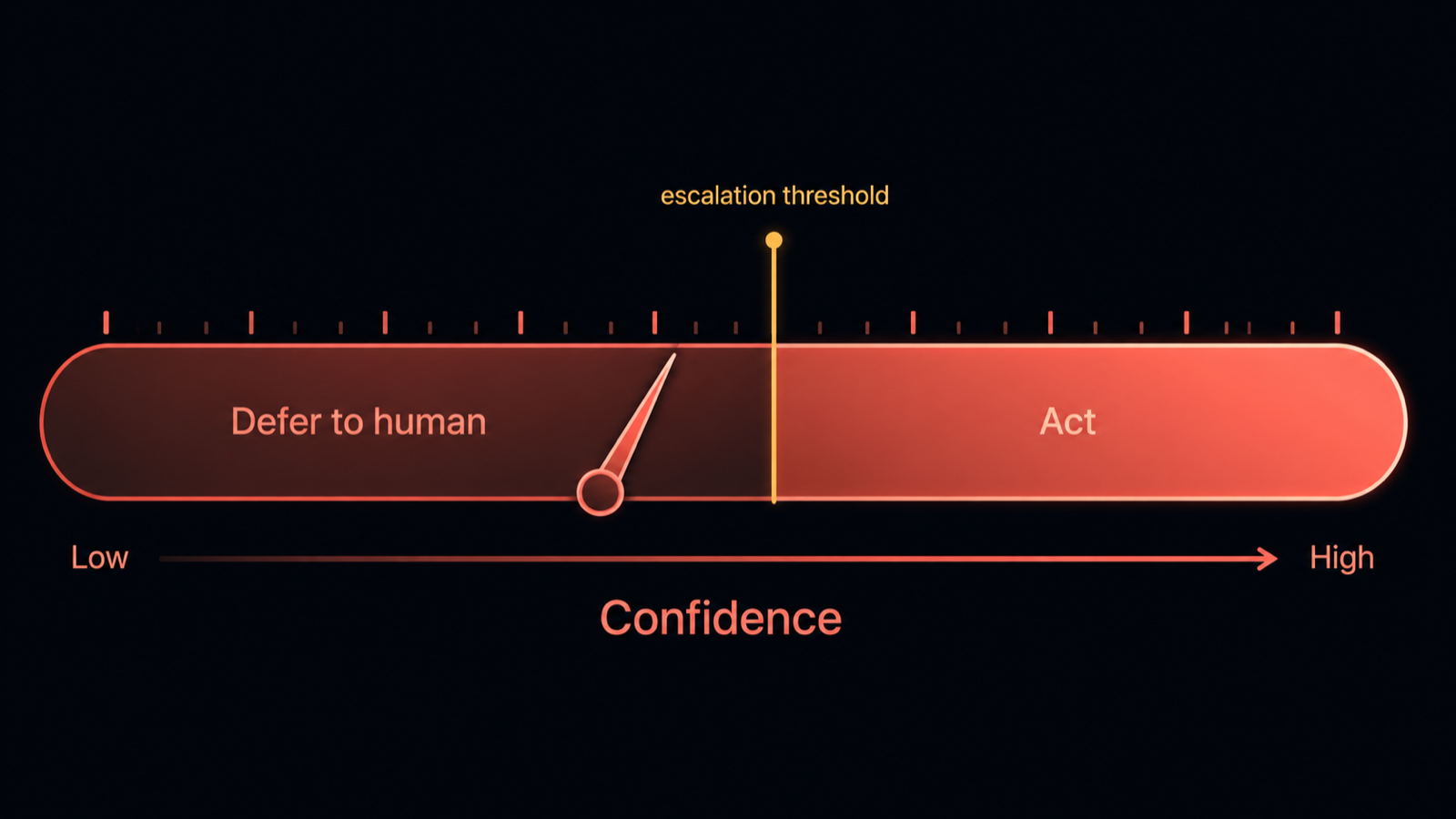
A confidence gauge with an escalation zone: below the threshold the agent defers to a human, above it the agent acts. The skill is knowing where the needle sits. Diagram.
What goes wrong when an agent can't abstain?
It acts on a guess, and in an agent a guess becomes an action. A chatbot that bluffs gives a wrong answer; an agent that bluffs issues the refund, files the ticket, sends the email, or edits the record on the strength of a fact it invented. The earlier failures across these agents, the support bot quoting a policy that does not exist, the legal brief with fabricated cases, the tool call reported as done that never happened, all share this root: the system had no way to say "I am not sure, stop here." The harm scales with autonomy. The more an agent can do without a human, the more an unhedged guess can cost, and the more it matters that the agent can recognize its own uncertainty and hand off rather than push ahead.
Is hallucination really fixable, or inherent?
Fixable, according to the people who study it most. A common defense of hallucination is that it is an unavoidable property of language models. OpenAI's 2025 analysis rejects that: models demonstrably can abstain when uncertain, so the problem is not that they cannot say "I don't know", it is that we have not rewarded them for it. A 2026 Nature paper makes the same point from the evaluation side, that grading for accuracy actively incentivizes hallucination. The implication is practical, not philosophical: you reduce hallucination by changing incentives and adding abstention, not by waiting for a model that never errs. That is good news, because it means the fix is in your hands, in how you score, threshold, and escalate, rather than out of reach in someone else's training run.
How do you design abstention and escalation?
| Mechanism | What it does |
|---|---|
| Reward "I don't know" | Score abstention above confident error in your own evals, so you select for honesty |
| Calibrate confidence | Make the agent's confidence track real accuracy, then trust it as a signal |
| Set escalation thresholds | Below a confidence bar, the agent defers instead of acting |
| Defer high-stakes actions | Route irreversible or sensitive actions to a human regardless of confidence |
| Verify before acting | Confirm the supporting fact exists before the agent commits to an action |
| Make "stop and ask" first-class | Treat asking a human as a successful outcome, not a failure |
The pattern is that an agent which cannot say "I don't know" will say something wrong instead, confidently, and then act on it. Reward honest uncertainty in how you evaluate, calibrate the agent's confidence so it becomes a usable signal, and route low-confidence and high-stakes moments to a human. None of that is a bigger model, which can be even more convincingly wrong. It is a layer that knows the edge of what the agent knows and stops there, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Isn't hallucination just inherent to LLMs?
The research says no. OpenAI's 2025 analysis shows models can abstain when uncertain, so the issue is that accuracy-only scoring rewards guessing, not that "I don't know" is impossible. Change the incentive and add abstention and the rate drops.
Why would a model bluff instead of admitting uncertainty?
Because it was graded that way. On a scoreboard that counts only right answers, a guess sometimes scores and an abstention never does, so the model is optimized to produce a confident answer even when unsure.
How do I know when to escalate to a human?
Use two triggers: confidence below a calibrated threshold, and stakes above a line. Low confidence on anything, or any irreversible or sensitive action, should defer to a human even when the agent is confident.
What's the single most useful change?
Score abstention above confident error in your own evaluations. Once "I don't know" beats a wrong guess on your scoreboard, you start selecting for an agent that hands off instead of bluffing.