

Short answer. Your agent gives a stale or contradictory answer because the retrieval layer handed it context that no longer matches reality, or handed it two chunks that disagree, and the model resolved the clash by trusting its own training instead of the evidence. Fix freshness and conflict-handling in the retrieval layer and the answers get reliable. The model is rarely the part that is broken.

A current fact and a stale one reach the agent at once. It commits to the wrong one, confidently. Hero image.
Key facts.
- Knowledge conflict is a leading driver of hallucination, not an edge case: ConflictBank built 7,453,853 claim-evidence pairs to measure it and names three causes, misinformation, temporal change, and semantic divergence (Su et al., ConflictBank, arXiv:2408.12076, NeurIPS 2024).
- When retrieved evidence conflicts with what the model already believes, accuracy drops 9.7% to 29.9%, and the model fails two ways: it clings to its own prior, or it over-corrects to the wrong context (FaithfulRAG, arXiv:2506.08938, 2025).
- Stronger retrieval models are not safer here: they show a Dunning-Kruger pattern, over-trusting internal memory even when the supplied evidence is correct (Jin et al., Tug-of-war, arXiv:2402.14409, 2024).
What does stale or conflicting context actually mean?
Two distinct failures wear one symptom. Stale context is when the index still holds last quarter's price, the old policy, or the deprecated API, because the document changed and the vectors did not. Conflicting context is when the top-k pulls several chunks that disagree, a current doc sitting next to an archived one, two sources with different numbers, and nothing tells the model which to believe. The taxonomy is well mapped: conflict between retrieved chunks (inter-context), and conflict between retrieved text and the model's trained-in knowledge (context-memory), with outdated facts a primary cause of both (Xu et al., Knowledge Conflicts for LLMs: A Survey, arXiv:2403.08319, 2024). The answer reads confident either way, which is what makes it costly.
Why does the model trust the wrong chunk?
Because resolving a conflict is a judgment call, and models bring biases to it. When the context disagrees with parametric memory, frontier retrieval models often side with memory, the effect Jin et al. call a Dunning-Kruger bias, alongside a pull toward whatever was most common in training and whatever confirms the existing prior. So even when you retrieve the correct, current fact, the model can quietly discard it for a familiar wrong one. FaithfulRAG put a number on the damage: 9.7% to 29.9% accuracy lost under conflict, split between over-confidence errors, where it ignores the context, and incorrect-match errors, where it follows misleading context. Retrieval did its job and the answer is still wrong.
Why does a fresh index still go stale?
Because most vector indexes were not built to change. HNSW and IVF, the common index types, do not support efficient incremental updates, so a changed document forces a costly rebuild or an awkward side index, and in the gap the old vector keeps getting retrieved. RAGPerf, an end-to-end benchmark built for live insert, update, and delete traffic, shows freshness and factual consistency degrading exactly under this pressure (RAGPerf, arXiv:2603.10765, 2026). Add embedding drift, where upgrading the embedding model silently shifts the vector space, and corpus drift, where new documents move the neighborhood, and a retriever that was accurate at launch starts surfacing stale neighbors months later with nothing obviously broken.
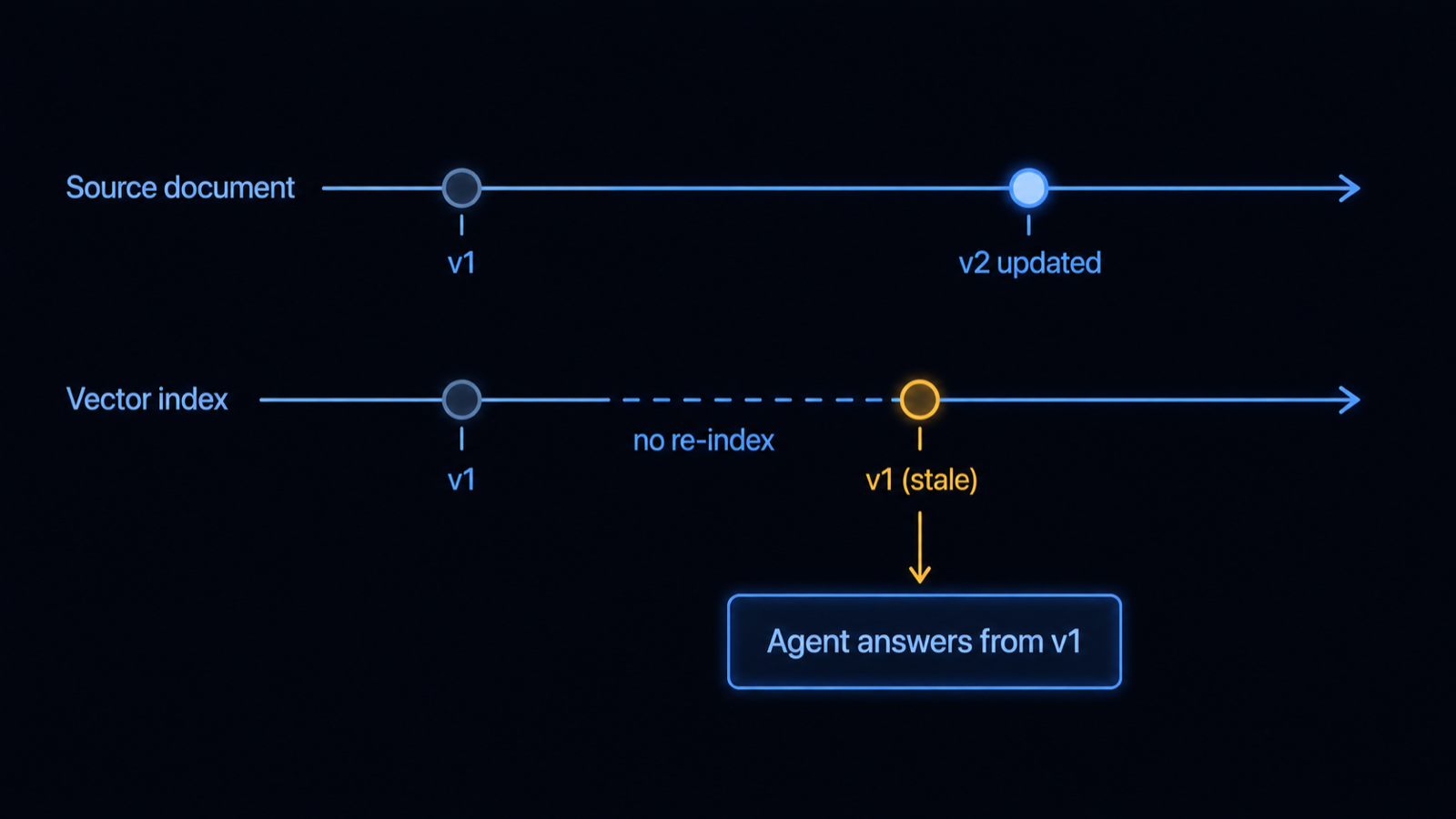
The source changed, the vector did not. A stale chunk and a current one reach the context together, and the conflict goes unresolved. Diagram.
What does this look like in a live system?
A production RAG analysis from DigitalOcean describes the same chain in deployed systems: an embedding model gets upgraded without re-indexing, or the corpus grows, the vector space shifts, and retrieval quietly starts returning outdated or off-target context, producing confident wrong answers that monitoring misses because nothing threw an error (DigitalOcean, 2026, reported). The tell is not a crash. It is a slow rise in answers that are fluent, plausible, and out of date, the kind a user only catches when they already know the right answer.
// Stamp every chunk so recency can win a conflict { "text": "Return window is 30 days.", "source": "policy/returns.md", "version_date": "2026-05-18", "supersedes": "2025-11-02" } // Retrieval boosts the newest version; the stale one loses.
How do you stop it?
| Symptom | Cause | Fix |
|---|---|---|
| Old value returned | Stale index, no re-embed | Timestamp every chunk, recency boost, scheduled re-index |
| Two chunks disagree | Intra-context conflict | Rerank and dedupe, prefer newest, surface the conflict |
| Right fact ignored | Parametric over-trust | Conflict-aware decoding (CD2), instruct to cite and reconcile |
| Slow accuracy decay | Embedding / corpus drift | Monitor drift, re-embed on model upgrade, hybrid search |
| Confident wrong answer | No conflict check | Post-retrieval contradiction check, allow "uncertain" |
The pattern under all of this is that retrieval cannot be fire-and-forget. Stamp every chunk with a date and let recency win when sources disagree. Re-embed when the model or the corpus moves, and watch for drift instead of waiting for complaints. Run a contradiction check before the model answers, and let it say it is unsure rather than pick a side blindly. None of that is a bigger model. It is an engineering layer that knows where your retrieval is current and trustworthy and where it is guessing, which is exactly what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Is this a model problem or a data problem?
Mostly a retrieval problem. The model resolves whatever context it is handed; if that context is stale or self-contradictory, a fluent wrong answer is the expected output. The fix is in freshness, conflict handling, and a grounding check, not in swapping the model.
How do I know my agent is using stale context?
Trace the retrieved chunks and their timestamps for a sample of answers. If the cited chunk predates the latest source edit, or two retrieved chunks disagree and neither is flagged, you have found it. Measuring only the final answer hides this entirely.
Which matters more, freshness or conflict handling?
Both, and they compound. Freshness keeps the wrong version out of the context; conflict handling decides correctly when two versions still reach it. Recency-aware ranking plus a contradiction check covers the common cases.
Does a bigger context window fix conflicting chunks?
No. A larger window often pulls in more contradictory sources, not fewer, and gives the model more to misweigh. Rerank to fewer, fresher, deduplicated chunks rather than flooding the context.