

Short answer. Your agent gives different answers to identical inputs because GPU inference is not deterministic by default: the kernels return slightly different numbers depending on how your request was batched with other traffic, and at temperature zero those tiny differences still flip an occasional token. Pin the inference, measure consistency instead of single runs, and verify each step, and you get reproducible, dependable behavior back.

One identical prompt, several diverging outputs from the same origin. The split happens in the serving stack. Hero image.
Key facts.
- Temperature zero does not mean deterministic: sampling 1,000 completions at temperature 0 of one open model produced 80 distinct outputs, the first divergence at token 103, because inference kernels are not batch-invariant (Thinking Machines Lab, Defeating Nondeterminism in LLM Inference, 2025).
- The cause is the serving stack, not your prompt: matrix multiplication, normalization, and attention kernels return slightly different numbers depending on the batch size they run in, and batch size shifts with server load you do not control (Thinking Machines Lab, 2025).
- The agent-level symptom is measurable: tau-bench's pass^k, the chance an agent solves the same task on all k tries, falls under 25% at k=8 in retail, so the same agent that passes once often fails on a repeat (Yao et al., tau-bench, arXiv:2406.12045, 2024).
Same prompt, same settings, different answer. How?
You send the identical request twice and get two different completions. The usual explanation, that the model is sampling randomly, is not the real story. The deeper cause is that GPU inference kernels are not batch-invariant: the low-level operations that run the model, matrix multiplication, normalization, attention, produce slightly different floating-point results depending on how many requests are batched together at that moment. Floating-point addition is not associative, so the order of the reductions, which the batch size changes, changes the last bits of the numbers. Those tiny differences occasionally flip which token is most likely, and from that token on the two runs diverge. Thinking Machines Lab demonstrated it directly: 1,000 temperature-zero completions of the same prompt yielded 80 distinct outputs (Defeating Nondeterminism in LLM Inference, 2025).
Why does temperature zero not make it deterministic?
Because temperature controls sampling, and the variance lives upstream of sampling. At temperature zero the model greedily takes the single most probable token at each step, which should be perfectly repeatable. It is not, because the probabilities themselves shift run to run when the kernels are batch-variant. Your request gets batched with whatever other traffic the server is handling that millisecond, the batch size changes, the numbers change, and the greedy choice occasionally lands on a different token. In the Thinking Machines test the completions agreed up to token 103 and then split, with no randomness in the sampler at all. So turning temperature to zero removes the obvious source of variance and leaves the structural one untouched.
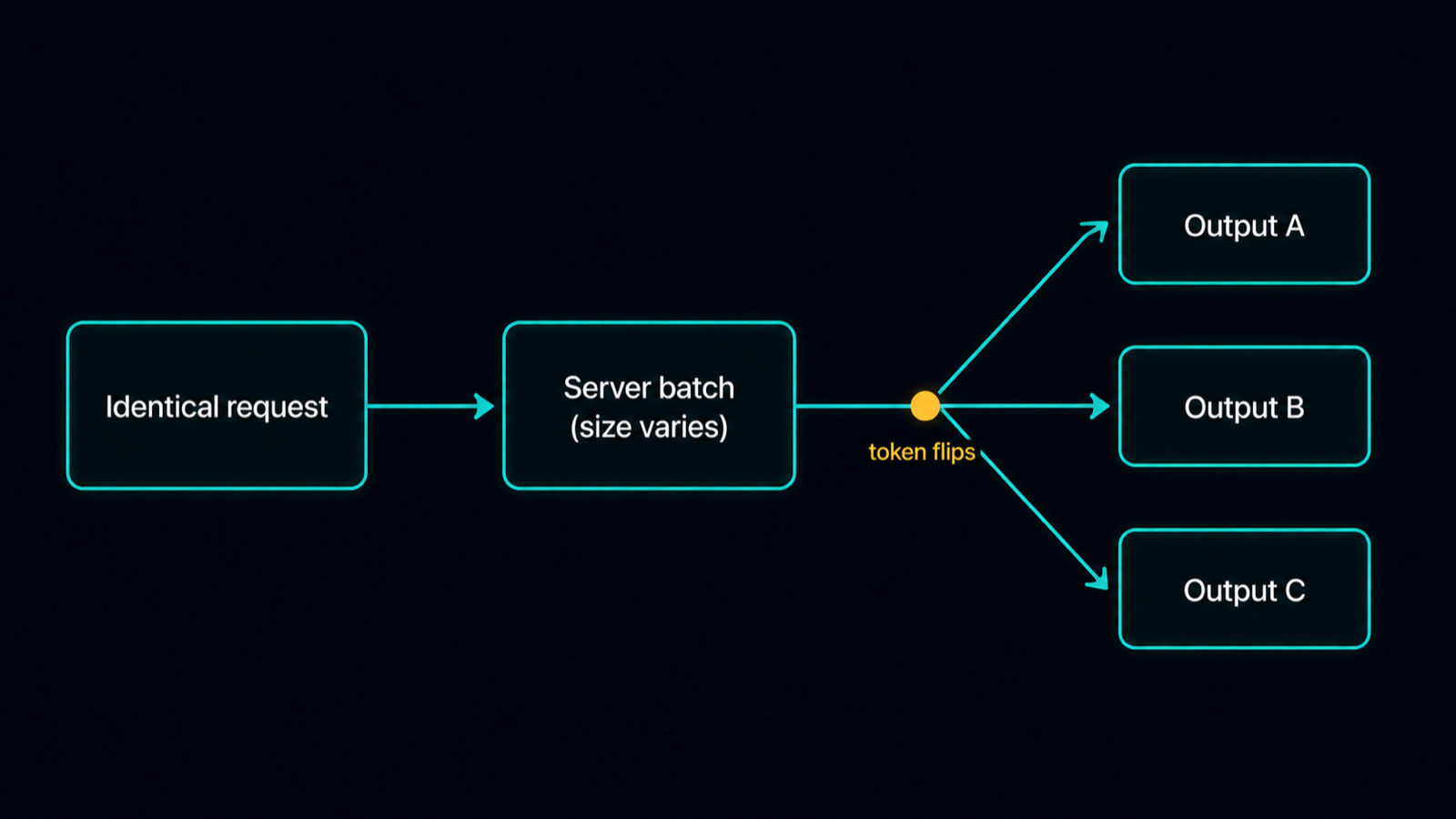
Identical request, variable batch, divergent output. The batch size you do not control changes the math. Diagram.
Why does run-to-run variance wreck your agent?
Because an agent is a chain, and a divergence at one step changes every step after it. A single-shot chatbot can absorb a little variance. An agent that plans, calls tools, reads results, and decides the next action will, on a different token at step two, take a different branch and reach a different outcome. tau-bench captures this with pass^k, the probability an agent solves the same task across all k attempts, and it collapses below 25% at k equals 8 in the retail domain (arXiv:2406.12045). The damage is threefold: evaluations are noisy, so you cannot tell a real improvement from luck; bugs are hard to reproduce, because the failing run will not fail again; and customers get inconsistent answers to the same question. None of that is the model being wrong. It is the same model giving different right-ish answers each time.
# One run tells you almost nothing. Measure consistency. runs = [run_agent(task) for _ in range(8)] pass_8 = all(r.success for r in runs) # did it pass every single time? # And pin what you can control client.generate(prompt, temperature=0, seed=42)
How do you get reproducibility back?
| Symptom | Cause | Fix |
|---|---|---|
| Temp-0 still varies | Batch-variant kernels | Batch-invariant kernels / deterministic inference mode |
| Cannot reproduce a bug | Run-to-run divergence | Pin seed, request deterministic settings, log full inputs |
| Noisy eval scores | Single-run measurement | Measure pass^k, not pass^1 |
| Divergent agent branch | Early token flip compounds | Verify each step before it advances the loop |
Treat determinism as something you engineer, not something you assume. At the infrastructure level, batch-invariant kernels, which Thinking Machines Lab released, make the math return the same result regardless of batch size, restoring bit-for-bit reproducibility, and deterministic-inference modes are appearing in serving stacks. Where you do not control the kernels, pin what you can: fix the seed, request deterministic settings from your provider, and log full inputs so a run can be replayed. At the agent level, stop trusting a single run to tell you anything: measure pass^k rather than pass^1 so reliability is part of the evaluation, and verify each step so a divergent branch is caught instead of silently shipped. None of that is a smarter model. It is a reliability layer that turns a probabilistic component into a dependable one, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Isn't this just temperature? Set it to zero.
Temperature zero removes sampling randomness but not the structural variance. The numbers feeding the greedy choice still shift with batch size, so identical temperature-zero runs still diverge, as the Thinking Machines test showed with 80 distinct outputs from one prompt.
Is the model broken if it gives different answers?
No. Each answer can be individually fine. The problem is consistency: you cannot reproduce a result, trust an eval delta, or promise a customer the same answer twice, which is a reliability problem, not a correctness one.
Why does this matter more for agents than chatbots?
Because agents chain steps. A single divergent token early in the run sends the agent down a different branch of tool calls and decisions, so small numerical variance becomes a different outcome, which is why pass^k drops so sharply.
How do I make my evals trustworthy?
Report pass^k across repeated runs instead of a single pass^1 score, pin inference settings, and log full inputs and outputs. That separates a real improvement from run-to-run noise.