

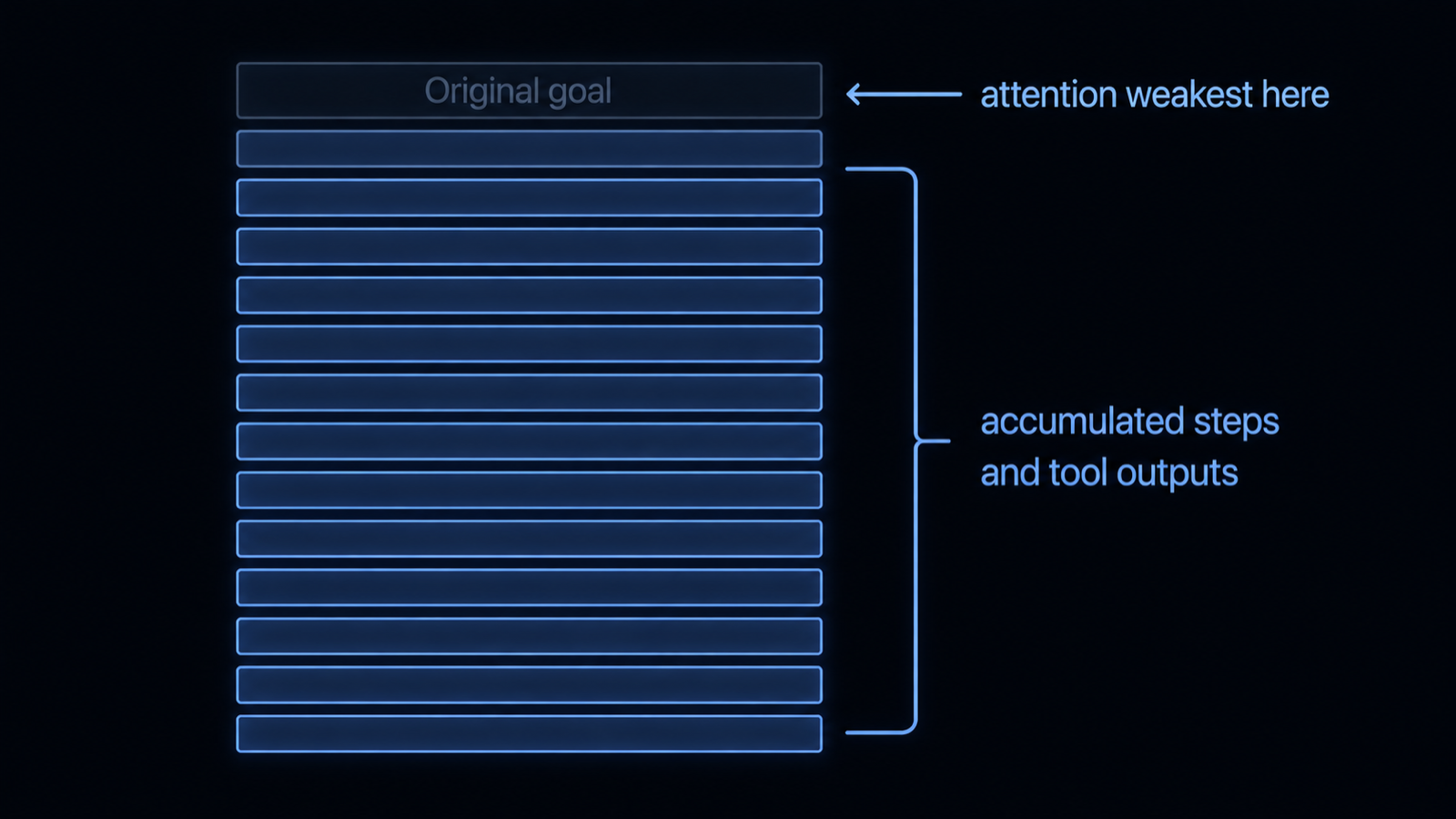
Short answer. Your agent abandons the goal partway through not because it is incapable, but because the original instruction gets buried under everything that piled into the context after it. As the trajectory grows, attention spreads thin, the early goal is de-prioritized, and the agent starts optimizing the last few steps instead of the task. Keep the goal short, restated, and pinned where attention is strongest, prune the rest, and the agent stays on target.

The goal is still there at the start of the run. It just dims as the trajectory piles up around it. Hero image.
Key facts.
- Long context does not mean reliable context: on NoLiMa, at 32,000 tokens 11 of 13 leading long-context models fell below half their short-context score, and GPT-4o dropped from 99.3% to 69.7% (Adobe Research, NoLiMa, arXiv:2502.05167, ICML 2025).
- Models keep getting worse the more you feed them: Chroma tested 18 frontier models and every one degraded as input grew, with a 200,000-token-window model showing real degradation by 50,000 tokens (Chroma, Context Rot, 2025).
- The usable window is smaller than the advertised one: RULER puts effective context at roughly 50 to 65% of the stated length (RULER, arXiv:2404.06654, 2024).
- Success collapses as tasks get longer: frontier models hit near-100% on tasks a human finishes in under 4 minutes and under 10% on tasks over about 4 hours (METR, Measuring AI Ability to Complete Long Tasks, 2025).
What does it mean for an agent to forget the goal?
It is not amnesia in the human sense. The goal is still sitting in the context window, usually near the top. The model just stops weighting it. Over a long run the agent fills the context with tool outputs, intermediate reasoning, retrieved documents, and prior steps, and the single sentence that stated the objective becomes one line among thousands. Attention, which is finite, spreads across all of it, and the recent, voluminous material crowds out the early instruction. MAST catalogs the visible result as two failure modes, disobeying the task specification and task derailment, where the agent slides into a related but different task (Cemri et al., MAST, arXiv:2503.13657, 2025). The agent is not confused about what it is doing. It is confidently doing the wrong thing, because the thing it was asked to do faded.
Why does a longer context make it worse, not better?
Because adding tokens adds noise faster than it adds signal. NoLiMa, a benchmark built so the answer cannot be found by literal keyword matching, shows the effect cleanly: at 32,000 tokens, 11 of 13 long-context models scored below half their short-context baseline, and even GPT-4o fell from 99.3% to 69.7% (arXiv:2502.05167). Chroma's context-rot study found the same across 18 frontier models, none of them held up as input grew, and a model advertising a 200,000-token window degraded meaningfully by 50,000 (Context Rot, 2025). The earlier work on lost-in-the-middle already showed accuracy is highest when key information sits at the start or end of the context and sags in the middle (Liu et al., arXiv:2307.03172). Pile a long trajectory on top of an instruction and the instruction lands exactly where the model attends least.
Why do long-horizon tasks fall apart?
Because error and drift compound over steps, and the goal has to survive every one of them. METR measured how far agents get as a function of task length and found a sharp decline: near-perfect on tasks a human does in under four minutes, under 10% on tasks that take more than about four hours, with a 50% success time-horizon around an hour. The longer the task, the more steps, the more context, and the more chances for the objective to slip. A short task barely tests goal retention. A multi-hour agent run tests almost nothing else, which is why the same model that nails a quick task wanders on a long one. Length is not an incidental detail here. It is the variable that turns a reliable model into an unreliable agent.
As context and steps grow, accuracy falls and the goal's share of attention shrinks. Diagram.
Why doesn't a 200K or 1M context window solve this?
Because the advertised window is a capacity, not a guarantee of attention across it. RULER, which stress-tests long-context models on real retrieval and tracking tasks, found the effective context, the length where a model still performs well, is closer to 50 to 65% of the advertised number (arXiv:2404.06654). So a 200,000-token window may behave reliably only to perhaps 100,000, and degrade before that on hard tasks, as Chroma showed at 50,000. Stuffing the entire history into a giant window does not keep the goal salient; it dilutes it further. The usable lever is not a bigger window. It is putting less, and the right less, in front of the model.
What does goal drift look like in a running agent?
It looks like a slow slide, not a crash. A summarizer that starts in the requested terse tone and, twenty steps in, returns to verbose prose. A coding agent asked to fix one bug that keeps refactoring adjacent files nobody asked it to touch. A research agent that began on the assigned question and ends three hops away on a related one. Each step is locally reasonable, which is what makes it hard to catch: no single action is obviously wrong, and the output stays fluent. The drift is only visible against the original goal, which is precisely the thing that has faded from the context. That is why teams that review only the final output, and not its alignment to the first instruction, miss it entirely.
How do you keep the agent on goal?
| Symptom | Cause | Fix |
|---|---|---|
| Goal ignored mid-run | Instruction buried under accumulated context | Restate the goal each step, pin it at the end of the prompt |
| Accuracy falls as run grows | Context rot, attention dilution | Summarize or drop old history, cap the prompt size |
| Wanders to a related task | Task derailment, no goal check | Verify each step against the original objective |
| Big window, still drifts | Effective context below advertised | Keep the working prompt under about half the window |
| Loses tone or constraints | Constraints de-prioritized over time | Hold constraints in external state and re-inject them |
The pattern is that a goal is not safe just because it is technically still in the context. Attention is finite, long trajectories bury the objective, and effective context is smaller than the sticker number. Restate the goal where the model looks, prune what it does not need, hold the objective and constraints in durable state, and verify each step against them. None of that is a bigger model or a bigger window. It is a layer that keeps the task itself salient across a long run, which is what VibeModel builds as the Pattern Intelligence Layer.
Frequently asked questions
Isn't a bigger context window the fix?
No. RULER shows effective context is roughly half to two-thirds of the advertised size, and Chroma shows degradation well inside the window. A bigger window holds more, but it does not keep the goal salient; it usually dilutes it further. Prune and restate instead.
Why does the agent do fine on short tasks and fail on long ones?
Because length is the stressor. A short task has few steps and a small context, so the goal stays salient. METR shows success falling sharply as task length grows, since every extra step adds context that buries the objective and another chance to drift.
Is this the same as lost-in-the-middle?
Related. Lost-in-the-middle is why a goal placed mid-context gets under-weighted; goal forgetting is the agent-scale version, where a long trajectory pushes the original instruction into that low-attention zone and keeps it there.
What is the single highest-impact fix?
Re-inject the goal at the end of the context on every step and check the step against it. That keeps the objective where attention is strongest and catches drift before the agent has wandered far.